Analysis of "The Anatomy of a Large-Scale Hypertextual Web Search Engine - Sergey Brin and Lawrence Page"
구글 창업자들이 2002년 구글 서치엔진의 시스템에 대하여 논문을 발표한적이 있었다. 비록, 20년전의 논문이지만 우리는 이것을 분석함으로써 그들이 어떤 철학을 가지고 아키텍처를 구성하였는지를 살펴볼수가 있고, 현재 그들의 시스템이 어떤 아키텍처로 구성되어있는지는 구글 핵심 관계자 이외에는 알 수 없는것이지만 그 기본 철학은 변하지 않았을것이라 믿는다. 그리고 그 기본 철학을 바탕으로 그들의 시스템은 계속해서 발전해나가고 있을터이니 우리 SEO를 연구하는 사람들도 그 기본 철학을 바탕으로 그들의 매커니즘을 예측하며, 우리의 Optimization작업을 발전시켜 나가야겠다.
1. Goggle Architecture Overview
논문에서는 architecture 이외에 다른 내용도 포함되어 있지만, 이 블로그는 시스템 아키텍쳐 중심으로만 분석이 할 예정이다. 전문을 읽고 싶은 사람은 The Anatomy of a Large-Scale Hypertextual Web Search Engine1) 에서 찾아볼 수 있다.
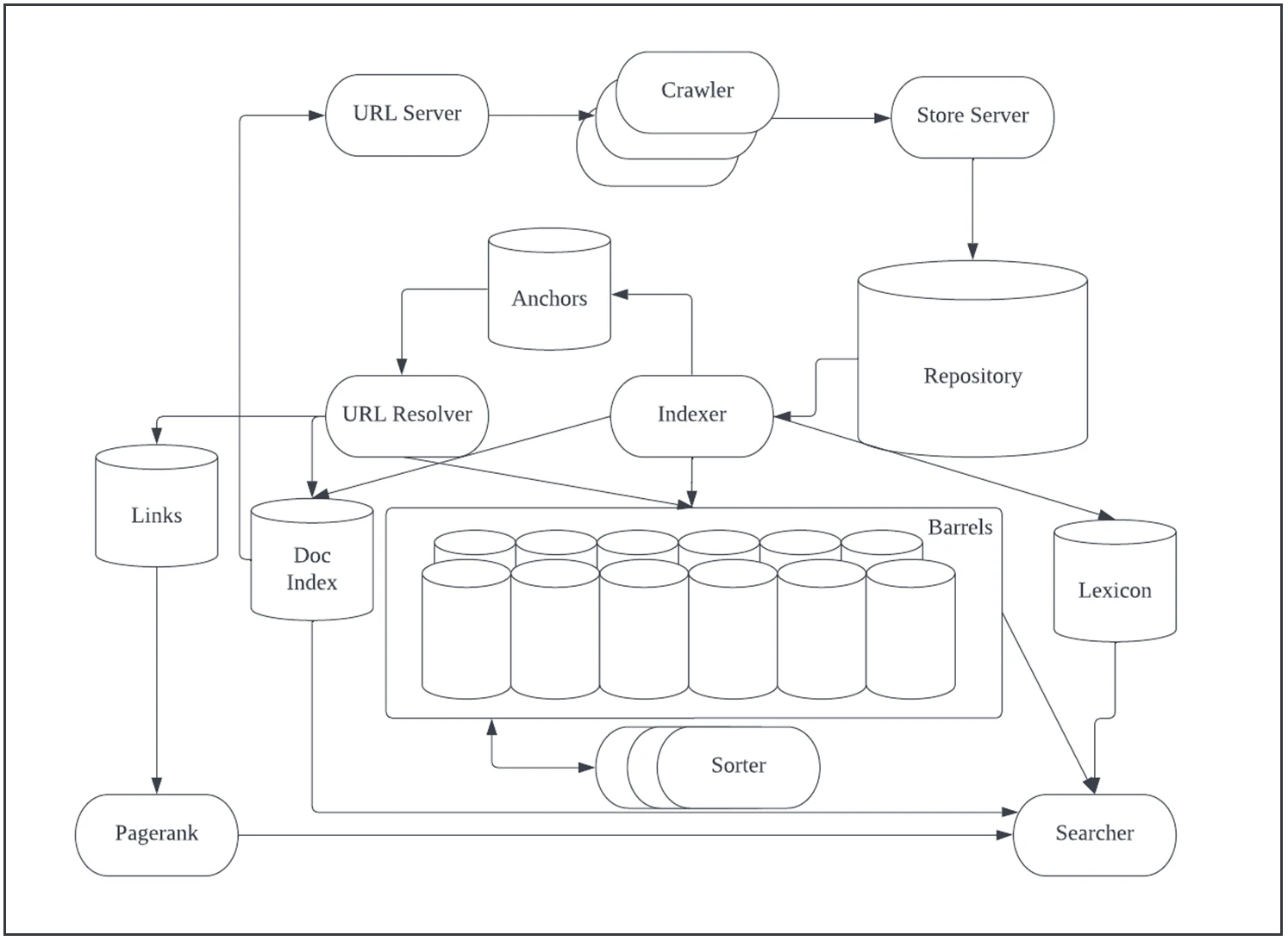
Figure 1. High Level Google Architecture(Sergey Brin and Lawrence Page 1998)1)
구성요소
Crawler : 크롤러는 각 웹사이트를 돌아다니면서 해당 Page에 있는 내용을 다운로드하는 역할을 한다. 기본적으로 Crawler가 우리의 웹사이트에 와서 아무 문제없도록 하기 위해서 테크니컬 SEO가 많이 사용된다. 어느 페이지는 Crawler가 수집이 가능하고, 어느 페이지는 안되어야 하는지를 각 사이트에서는 robots.txt파일을 통해 Crawler를 위해 설정을 해야 한다. 즉, Crawler에게 문을 열어줄것인지 말것인지를 설정하는것이다. 또 다른 설정은 sitemap.xml을 설정해야 하는데, 이것은 website에서 page rank로서 전해줄 url에 대한 여러가지 세부적인 설정을 할 수 있다. 각각의 Crawler에게 수집할 URL을 전달하면서 각각의 우선 순위값을 정해줄 수 있다. 또한 내용이 바뀌는 주기를 설정함으로써 새로 업데이트된 내용을 Crawler가 수정할 수 있도록 도와주는 장치이다.
URL Server : 크롤러가 방문해야 할 URL목록을 제공해주는 서버이다. 구글 시스템 아키텍처에서 다운로드한 페이지를 분석하여 url들을 추출하고는 URL Server에 저장한다. 그 저정된 URL은 다시 Crawler가 활용한다.
StoreServer : 크롤러가 가져온(다운로드 해서) 각 웹사이트의 내용을 압축하여 Repository에 저장하는 역할을 한다.
Repository : 압축된 웹페이지를 저장하는 저장소이다.
Indexer : 인덱서는 레파지토리에 있는 압축된 문서를 풀어 그 문서에 있는 내용을 여러가지 카테고리를 가지고 분석한다. "Hits"라고 하는 단어들을 분석을 해내는데, 분석된 단어들은 Barrel에 분류되어 저장된다. 우리가 SEO 작업을 할때 가장 연관된 곳이 바로 이것으로 보인다. Page내 Text가 H1~H6Tag를 사용하여 되었는지, 이미지의 Alt Tag가 무엇인지, Title과 Description등 여러가지 SEO 장치들을 가지고 Indexer가 작업을 하는것으로 보인다. Hits는 Fancy hits와 Plain hits로 나눠지는데, Fancy hits는 url, title, anchor, meta tag에 hits가 있는 경우이고, Plain hits는 그 나머지에서 hits가 있는 경우이다. 우리가 Page에서 title이나 description tag에 키워드를 넣고, url을 유의미한 키워드로 만든다면 그러한 정보들은 Fancy hits로 분류되어 관리된다는 것을 알 수 있다. 그 밖에 본문에서 글자의 크기나 여러가지 요소를 가지고 hits 목록을 만드는 것이 Plain hits이다. Fancy hits가 Plain hits보다 더 중요하게 다뤄진다는 내용은 어디에서도 찾아볼수가 없다. 그리고 또 그렇게 관리되는 구조 자체가 20년이 지난 지금 달라졌을 수도 있다. 하지만, 구글에서 그러한 구분을 만들어서라도 사용자의 의도와 페이지의 의도를 파악하려는 노력은 분명히 계속되고 있음을 알 수 있다. SEO의 입장에서는 Fancy Hits가 되든 Plain Hits가 되든 어느 하나 중요하지 않은게 없다는 것을 알고 Optimization의 노력을 계속해야 한다. 인덱서는 또한 URL을 추출하여 anchors file에 정리되어 저장한다.
Sorter : Indexer와 협업을 통해 문서 분석작업을 같이 하고, wordID(추출된 키워드는 내부적으로 wordID로 관리되고 있음을 짐작할 수 있다)에 따라 역방향으로 자료를 찾아갈수 있도록 데이타를 정렬한다. 역방향으로 찾아간다는 것은 단어로부터 시작하여 문서를 찾아가는 것을 뜻하고, 문서로부터 시작하여 단어들을 추출을 해내는 방향은 fowared index이다.
Barrels : Indexer가 분류한 Hits( SEO작업에 주로 쓰이는 Keyword 라고 하는것이 맞는듯 )들을 분류방법에 따라 저장해놓는데 쓰인다.
Anchor file : 인덱서가 분류해놓은 URL 저장소이다.
URL Resolver : anchor file 저장된 각 Url에 docID를 부여한다음, 베럴에 있는 forward 인덱스에 맵핑하여 그 정보를 저장한다.
PagerRank : LinkDatabase에 있는 데이타를 가지고 PageRank값을 계산하는데 사용된다.
Lexicon : 인덱서에 추출한 단어들의 집합이다.
Searcher : 추출되 단어들, Sorter가 만들어낸 역인데스( 단어로부터 페이지를 찾아갈수 있도록 하는 방향 ), PageRank 정보를 가지고 검색결과를 만들어낸다.
구성 요소 파트에서 주목할 지점은 20년전의 아키텍처 상에서 PageRank가 계산되는 지점을 주목할 필요가 있다. 그 당시에는 PageRank가 Anchor File, 즉 추출되 URL기반으로 계산되었다는 것을 알 수 있다. 하지만 구글 창립자들이 이 논문을 공개를 하고 이러한 매커니즘의 노출로 인하여 link를 매매하는 일이 많아지면서 PageRank가 오염되기 시작하였다. 그래서 그 이후로는 단순히 url link로 부터 계산되는 PageRank 계산값에 여러가지 다른 요소가 포함되어 포괄적으로 계산되어지기 시작하였다.
2. Search Mechanism
Figure 2. Google Query Evaluation(Sergey Brin and Lawrence Page 1998)1)
Parse the query. : 사용자가 알고 싶은 부분을 구글에 단어를 넣고 서치를 시작한다.
Convert words into wordIDs. : Google 시스템은 서치 단어들을 wordID로 변경한다
Seek to the start of the doclist in the short barrel for every word. : Sorter가 만들어놓은 역인덱스(inverted index)를 가지고 barrel을 찾기 시작한다.
Scan through the doclists until there is a document that matches all the search terms. : 문서를 찾는다.
Compute the rank of that document for the query. : 찾은 문서에 대해 Page Rank를 계산한다.
If we are in the short barrels and at the end of any doclist, seek to the start of the doclist in the full barrel for every word and go to step 4. : 전체 Barrel에 대해, 문서를 찾는 과정을 반복한다.
If we are not at the end of any doclist go to step 4.
Sort the documents that have matched by rank and return the top k. : 사용자가 찾는 단어와 매칭되는 문서들의 PageRank를 계산하여 검색결과를 보여준다.
3. Ranking System
"Google considers each hit to be one of several different types (title, anchor, URL, plain text large font, plain text small font, ...), each of which has its own type-weight."(Sergey Brin and Lawrence Page 1998)1) 구글은 text의 여러가지 요소를 가지고 그 콘테트의 의도를 판단하려고 한다.
"Google counts the number of hits of each type in the hit list. Then every count is converted into a count-weight. Count-weights increase linearly with counts at first but quickly taper off so that more than a certain count will not help."(Sergey Brin and Lawrence Page 1998)1) 본문 텍스트 주요 단어가 몇번 나오는지 체크를 하기는 하지만, 어느정도 이상이 되면 무시한다고 되어있다. 이것의 의미는 SEO작업에서 Contents를 작성할 때 무의미하게 같은 단어를 여러번 적는다고 해서 그것이 Ranking 시스템에 아무런 효과를 내지 않는다는 것을 알아야 한다. 하지만, 어느정도의 반복은 유의미한 영향을 줄수있다는 것도 우리는 여기서 알 수 있다.
"Now multiple hit lists must be scanned through at once so that hits occurring close together in a document are weighted higher than hits occurring far apart. The hits from the multiple hit lists are matched up so that nearby hits are matched together."(Sergey Brin and Lawrence Page 1998)1) 여러단어를 사용하여 검색을 할 경우 다소 복잡한 계산이 들어가는데, count-weights와 type-prox-weights를 가지고 계산을 한다고 되어 있다. 그리고 같은 문서 내에서 해당 hits가 얼마나 가까이에 있는가도 판별기준의 하나였던거 같다. 비록 지금 이 계산 방식이 여전히 유효하다고 그 누구도 확신할 수는 없지만, 키워드의 선택과 그 키워드의 위치가 여러 Ranking Factor중에 하나일 가능성은 여전히 존재한다.
4. Conclusion
20년도 더 된 구글의 논문을 살펴본결과 그때와 지금의 그들의 기본 매커니즘은 High Level에서는 크게 달라지지 않았다고 생각한다. 하지만 언제나 그렇듯, Low Level에서 Google은 그들의 기술을 계속 발전시켜왔을 것이며, 나를 비롯하여 대부분의 사람들은 그 세부적인 것들에 대해 알 수가 없다. 다만 현 시대의 기술 트랜드를 보고 있노라면, 구글 역시 더 효율적인 Indexer와 Sorting을 위해 인공지능이라 일컬어지는 여러가지 최신 데이타분석 알고리즘이 많이 개발되었을 것으로 본다. 그러면서 더욱더 인간들이 검색어로 사용하는 문장을 이해하고 그것의 의도를 파악하는 기술이 점점 더 올라간다고 본다면, SEO Expert로서 우리는 컨텐츠의 의도를 더욱더 분명히 하고 Search Engine에게 명확한 Signal을 주기 위해서 할 수 있는 Technical적인 SEO 장치들을 더 명확하게 인지하고 사용할 필요가 있다. 또한 구글은 Localization에 대해서 많은 서비스를 개발하고 있다. Google Business Profile이 그중에 대표적인 서비스이고, 이러한 추세를 볼때 지역명은 그들의 키워드 추출 알고리즘에 주요한 변수로 작용하고 있음은 틀림없이 알 수 있다. SEO 담당자들은 그러한 점을 잘 활용할 필요가 있겠다.