Analysis of "The Anatomy of a Large-Scale Hypertextual Web Search Engine - Sergey Brin and Lawrence Page"
The founders of Google published a paper on the system of Google's search engine in 2002. Although it is a paper from 20 years ago, we can examine what kind of philosophy they have built their architecture with by analyzing this, and what kind of architecture their system is currently composed of can not be known except by key Google officials, but I believe the basic philosophy has not changed. And because their system has continued to develop based on that basic philosophy, those who study our SEO should predict their mechanism based on that basic philosophy and develop our optimization work.
1. Goggle Architecture Overview
Although the thesis includes other content besides architecture, this blog will analyze only the system architecture. Those interested in reading the full text can find it at The Anatomy of a Large-Scale Hypertextual Web Search Engine 1).
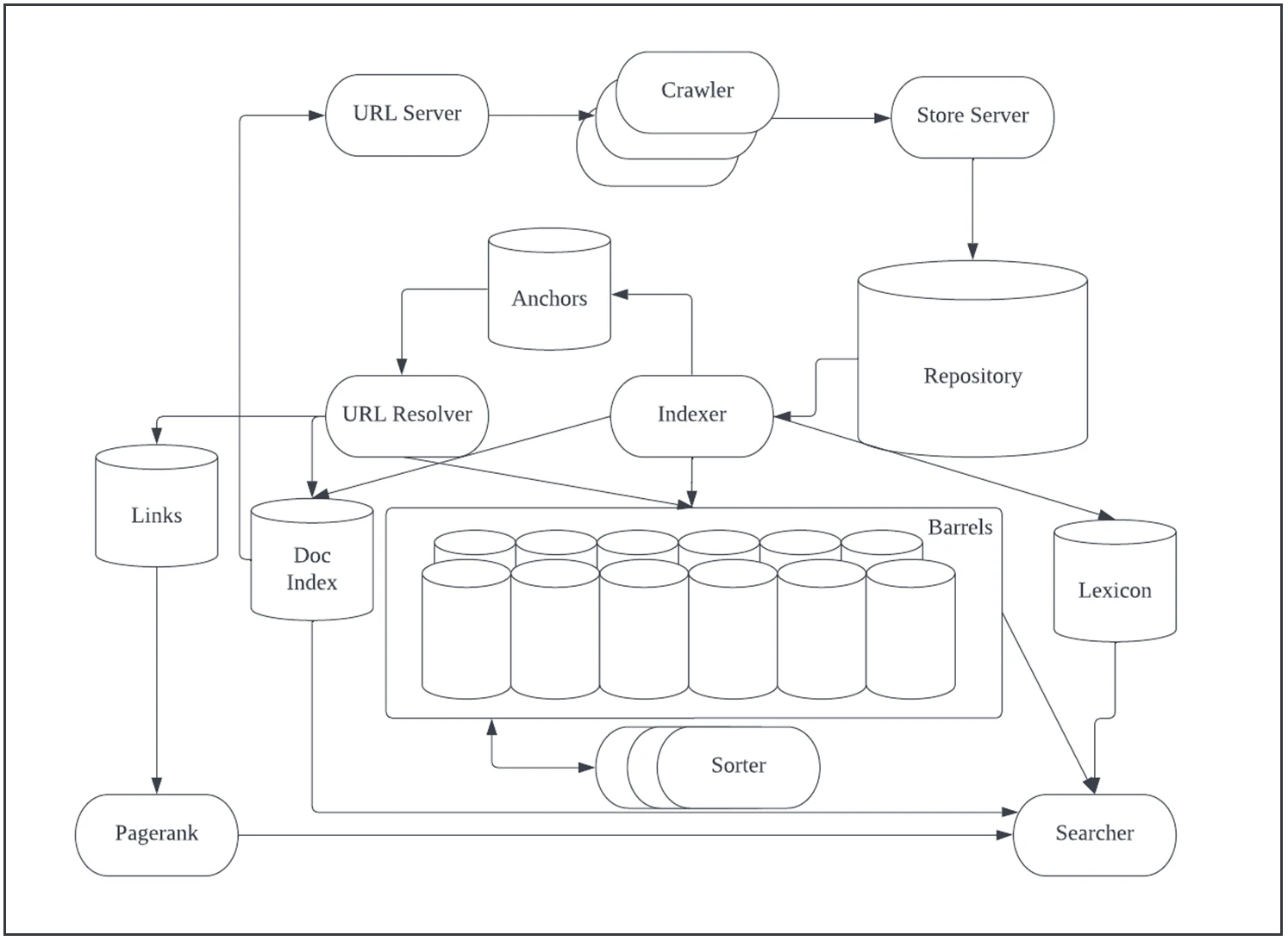
Figure 1. High Level Google Architecture(Sergey Brin and Lawrence Page 1998)1)
Component
Crawler : The crawler is responsible for traversing each website and downloading the contents of the corresponding page. Basically, technical SEO is used a lot to make sure that the crawler comes to our website and there is no problem. Which pages the crawler can collect and which pages should not be set for the crawler through the robots.txt file at each site. That is, it is to set whether to open the door to the Crawler or not. Another setting is sitemap.xml, which allows you to set various detailed settings for the url to be delivered as page rank on the website. You can set each priority value while passing the URL to collect to each crawler. In addition, it is a device that helps the crawler to modify the newly updated contents by setting the cycle of changing the contents.
URL Server : It is a server that provides a list of URLs to be visited by the crawler. Analyzes the downloaded page in the Google system architecture, extracts urls, and stores them in the URL Server. The saved URL is used by Crawler again.
StoreServer : It compresses the contents of each website that the crawler retrieves (downloads) and stores it in the Repository.
Repository : A storage for compressed web pages.
Indexer : The indexer unpacks the compressed documents in the repository and analyzes the contents of the documents into various categories. Words called "Hits" are analyzed, and the analyzed words are classified and stored in the barrel. This seems to be the most relevant place when we do SEO. It seems that the indexer is working with various SEO devices such as whether the text in the page uses H1~H6 tags, what is the alt tag of the image, and title and description. Hits are divided into Fancy hits and Plain hits. Fancy hits are when there are hits in the url, title, anchor, or meta tag, and Plain hits are when there are hits in the rest. If we put keywords in the title or description tag in the Page and make the url a meaningful keyword, we can see that such information is classified as Fancy hits and managed. Other than that, it is plain hits to create a list of hits based on the size of the text or various elements. I can't find anywhere that fancy hits are more important than plain hits. And the structure itself may have changed 20 years later. However, even if Google makes such a distinction, it can be seen that the effort to understand the intent of the user and the intent of the page is clearly continuing. From the standpoint of SEO, whether it is Fancy Hits or Plain Hits, you need to know that nothing is unimportant and you should continue the effort of optimization. The indexer also extracts the URLs and stores them organized in an anchors file.
Sorter : The sorter works with the indexer to analyze documents together, and sorts the data so that the data can be searched in the reverse direction according to wordID (you can guess that the extracted keyword is internally managed as wordID). Searching in the reverse direction means finding a document starting from a word, and the direction of extracting words starting from a document is a forwarded index.
Barrels : It is used to store the Hits classified by the Indexer according to the classification method.
Anchor file : This is the URL store classified by the indexer.
URL Resolver : After assigning docID to each URL stored in anchor file, it is mapped to the forward index in the barrel and the information is saved.
Links ( Database ) : It is a data store where docID and forward index are mapped.
PagerRank : It is used to calculate the PageRank value with the data in the LinkDatabase.
Lexicon : It is a set of words extracted by the indexer.
Searcher : Search results are created with the extracted words, the reverse index created by the sorter (direction to find a page from the word), and PageRank information.
In the component part, it is worth noting that the PageRank is calculated on the architecture of 20 years ago. At that time, you can see that the PageRank was calculated based on the Anchor File, that is, the extracted URL. However, as the founders of Google published this paper and traded links due to exposure of this mechanism, PageRank began to be polluted. So, since then, various other factors have been included in the PageRank calculation value calculated from the url link and started to be comprehensively calculated.
2. Search Mechanism
Figure 2. Google Query Evaluation(Sergey Brin and Lawrence Page 1998)1)
Parse the query. : Put a word into Google for the part you want to know and start a search.
Convert words into wordIDs. : Google system converts search words to wordID
Seek to the start of the doclist in the short barrel for every word. : It starts looking for barrels with the inverted index created by the sorter.
Scan through the doclists until there is a document that matches all the search terms. : Find the document.
Compute the rank of that document for the query. : Calculate the Page Rank for the found documents.
If we are in the short barrels and at the end of any doclist, seek to the start of the doclist in the full barrel for every word and go to step 4. : 전체 Barrel에 대해, 문서를 찾는 과정을 반복한다. For the entire barrel, repeat the document retrieval process.
If we are not at the end of any doclist go to step 4.
Sort the documents that have matched by rank and return the top k. : Search results are displayed by calculating the PageRank of documents that match the word the user is looking for.
3. Ranking System
"Google considers each hit to be one of several different types (title, anchor, URL, plain text large font, plain text small font, ...), each of which has its own type-weight."(Sergey Brin and Lawrence Page 1998)1) Google tries to judge the intent of the content based on various elements of the text.
"Google counts the number of hits of each type in the hit list. Then every count is converted into a count-weight. Count-weights increase linearly with counts at first but quickly taper off so that more than a certain count will not help."(Sergey Brin and Lawrence Page 1998)1) It checks how many key words appear in the body text, but if it exceeds a certain level, it is said to be ignored. The meaning of this is that when writing content in SEO work, you should know that meaninglessly writing the same word multiple times has no effect on the ranking system. However, we can also see here that a certain amount of repetition can have a significant effect.
"Now multiple hit lists must be scanned through at once so that hits occurring close together in a document are weighted higher than hits occurring far apart. The hits from the multiple hit lists are matched up so that nearby hits are matched together."(Sergey Brin and Lawrence Page 1998)1) When searching using multiple words, a rather complicated calculation is involved. And it seems that how close the hits are in the same document was also one of the criteria for determining. Although no one can be sure that this calculation method is still valid now, there is still a possibility that the keyword selection and the location of the keyword are one of several Ranking Factors.
4. Conclusion
As a result of looking at Google's papers that are more than 20 years old, I think that their basic mechanisms then and now have not changed much at the High Level. But, as always, at the Low Level, Google would have continued to advance their tech, and most people, including me, are unaware of the details. However, if you look at the current technology trends, I think that Google has also developed a lot of the latest data analysis algorithms called artificial intelligence for more efficient indexer and sorting. In the meantime, if we see that the technology to understand the sentences used by humans as a search term and to understand its intention is increasing, as SEO experts, we can make the intention of the content more clear and provide a clear signal to the search engine. SEO devices need to be recognized and used more clearly. Also, Google is developing many services for Localization. Google Business Profile is a representative service among them, and when you look at this trend, it is clear that the local name is acting as a major variable in their keyword extraction algorithm. SEO managers need to take advantage of that.